圖1
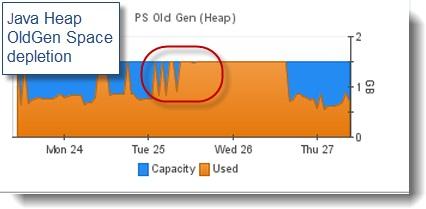
3.Java虛擬機垃圾回收過度
各位對“java.lang.OutOfMemoryError”這個錯誤信息是不是很熟悉呢����?由于JVM的內存空間過度消耗(Java堆����、本機堆等)而拋出的異常。
圖2
垃圾收集問題并不一定會表現(xiàn)為一個OOM條件����,過度的垃圾收集可以理解成是JVM GC線程在短時間里進行輕微或超量收集集合數據而導致的JVM暫停時間很長和性能下降?��?赡苡幸韵聨讉€原因:
與JVM的負載量和應用程序內存占用量相比�����,Java堆可能選擇的太小����。
JVM GC策略使用不合理。
應用程序靜態(tài)或動態(tài)內存占用量太大��,不適合在32位JVM上使用�����。
JVM OldGen隨著時間推移���,泄漏越來越嚴重����,而GC在幾個小時或者幾天后才發(fā)現(xiàn)����。
JVM PermGen空間(只有HotSpot VM)或本機堆隨著時間推移會泄露是一個非常普遍的問題;OOM的錯誤往往是觀察一段時間后���,應用程序進行動態(tài)調動���。
YoungGen和OldGen的比例空間與你的應用程序不匹配�。
Java堆在32位的VM上太大,導致本機堆溢出���,具體可以表現(xiàn)為OOM試著去鏈接一個新的Java EE應用程序����、創(chuàng)建一個新的Java線程或者需要計算本地內存分配任務。
建議:
觀察和深入理解JVM垃圾回收���。啟動GC�,根據健康合理的評估來提供所有的數據��。
記住����,GC方面的相關問題不會在開發(fā)中或者功能測試時發(fā)現(xiàn),它需要在多用戶高負載的測試環(huán)境下發(fā)現(xiàn)�����。
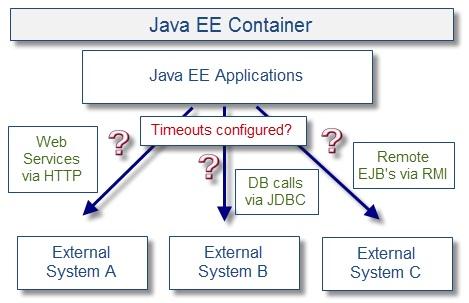
4.與外部系統(tǒng)集成過多或過少
導致Java EE性能差的第四個原因是高分布式系統(tǒng)�����,典型案例是電信IT環(huán)境���。在這個環(huán)境中��,一個中間件領域(例如,服務總線)很少會做所有的工作��,而僅僅是把一些業(yè)務“委托”給其他部分�,例如產品質量����,客戶資料和訂單管理�,到其他Java EE中間件平臺或遺留系統(tǒng)中,如支持各種不同的負載類型和通信協(xié)議的大型機����。
圖3
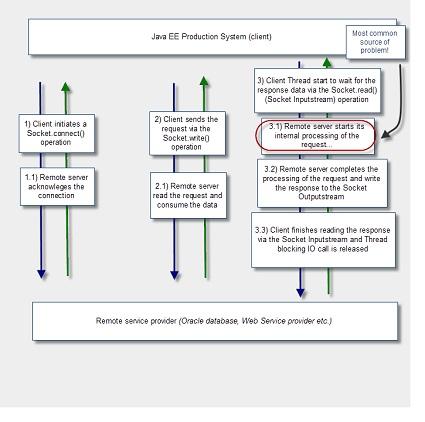
這樣的外部系統(tǒng)調用意味著客戶端的Java EE應用程序觸發(fā)創(chuàng)建或重用套接字鏈接從外部系統(tǒng)中讀寫數據�。根據業(yè)務流程的實施和實現(xiàn)可以配置成同步調用或異步調用���。需要注意的是���,響應時間會根據外部系統(tǒng)的穩(wěn)定狀況進行改變,所以通過適當的使用超時來保護Java EE應用程序和中間件也是非常重要的��。
圖4
下面這3種情況是經常出現(xiàn)問題和性能降低的地方:
同步和相繼調用太多的外部系統(tǒng)。
在Java EE客戶端應用程序和外部系統(tǒng)之間鏈接超時�����,使數據丟失或者值太高導致客戶端線程被卡住����,從而導致多米拉效應��。
超時�����,但程序仍正常執(zhí)行�,可是中間件不處理這種奇怪的路徑��。
最后��,建議多進行負面測試���,這意味著需要“人為”創(chuàng)造產生這些問題的條件,用來測試應用程序和中間件之間是如何處理外部系統(tǒng)錯誤�����。
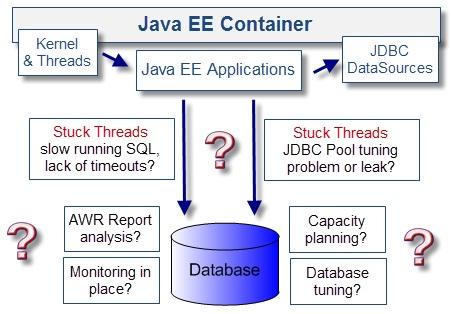
5.缺乏適當的數據庫SQL調優(yōu)和容量規(guī)劃
大家可能會對這一個感到驚奇:數據庫問題。大多數Java EE企業(yè)系統(tǒng)是依賴關系型數據庫處理復雜的業(yè)務流程���。一個基礎扎實穩(wěn)固的數據庫環(huán)境可以確保IT環(huán)境有規(guī)模的增長���,來支持日益不斷擴大的業(yè)務�。
圖5
在實際中����,與數據庫相關的性能問題是很常見的�����。由于多數數據庫事務處理都是由JDBC數據源執(zhí)行的(包括關系持久化API,例如Hibernate)�。而性能問題最初都會表現(xiàn)為線程阻塞。
以下是我在10年的工作中����,經常出現(xiàn)的關于數據庫方面的問題(以Oracle數據庫為例):
孤立的��,長時間運行的SQL。主要表現(xiàn)為線程阻塞��、SQL沒有進行優(yōu)化���、缺少索引��、非最佳的執(zhí)行計劃�、返回大量數據集等等。
表或行級數據鎖定�����。當提交一個雙階段事務模型時(例如��,臭名昭著的Oracle可疑事務)�。Java EE容器可能會留下一些未處理的事務等待最后的提交或回滾����,留下的數據鎖能觸發(fā)性能問題,直到最后的鎖被移除。例如中間件斷電或者服務器崩潰都可能引起這些情況發(fā)生���。
缺乏合理規(guī)范的數據庫管理工具����。例如Oracle里面的REDO logs,數據庫數據文件等�����。磁盤空間不足,日志文件不旋轉等都會觸發(fā)較大的性能問題和斷電情況����。
建議:
合理的容量規(guī)劃,包括負載和性能測試都是必不可少的����,優(yōu)化數據環(huán)境和及時發(fā)現(xiàn)問題�����。
如果是使用Oracle數據庫�����,確保DBA團隊定期審查AWR報告�����,尤其是在上下關聯(lián)的事件和根源分析過程中���。
使用JVM線程存儲和AWR報告查明SQL運行緩慢的原因或者使用監(jiān)控工具來做�����。
加強“操作”方面的數據庫環(huán)境(磁盤空間��、數據文件�、重做日志�����、表空間等)以適當的監(jiān)視和報警����。如果不這么做�,會讓客戶端IT環(huán)境出現(xiàn)較多的斷電情況和花許多時間進行故障調修����。
6.特定應用程序性能問題
下面關注的是比較嚴重的Java EE應用程序問題。關于特定應用程序性能問題����,總結了以下幾個點:
線程安全的代碼問題
通信API缺少超時設置
I/O、JDBC或者關系型API資源管理問題
缺乏適當的數據緩存
數據緩存過度
過多的日志記錄
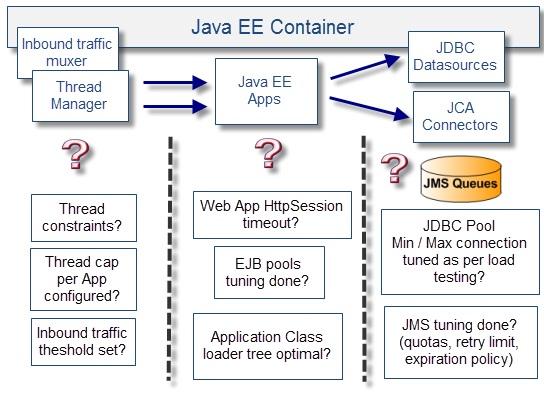
7.Java EE中間件調優(yōu)問題
一般Java EE中間件都已經夠用了�����,只是缺少必要的優(yōu)化。大多數Java EE容器都能有多種方案供你的應用程序和業(yè)務進程選擇�。
如果沒有進行適當的調整和實踐��,那么Java EE容器可能會處于一種消極的狀態(tài)。
下圖是視圖和檢查列表示例:
圖6
8.主動監(jiān)控不足
缺乏監(jiān)控,并不會帶來實際性能問題�����,但它會影響你對Java EE平臺性能和健康狀況的了解。最終�����,這個環(huán)境可以達到一個破發(fā)點�,這可能會暴露出一些缺陷和問題(JVM的內存泄漏�,等等)���。
以我的經驗來看����,如果一開始不進行監(jiān)控��,而是運行幾個月或者幾年后再進行���,平臺穩(wěn)定性將大打折扣。
也就是說���,改善現(xiàn)有的環(huán)境永遠都不會晚��。下面是一些建議:
復查現(xiàn)有Java EE環(huán)境監(jiān)測能力和找到需改進的地方�����。
監(jiān)測方案應該盡可能的覆蓋整個環(huán)境。
監(jiān)控方案應該符合容量規(guī)劃進程��。
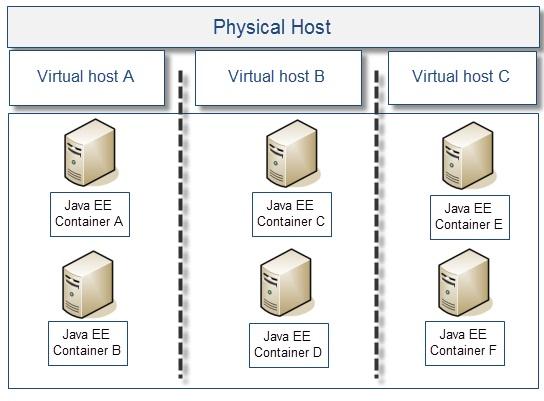
9.公共基礎設施硬件飽和
這個問題經常在有太多的Java EE中間件環(huán)境隨著JVM進程被部署到現(xiàn)有硬件上面時看到���。太多的JVM進程對有限的物理CPU核心來說是一個真正的程序性能殺手�。另外��,隨著客戶端業(yè)務的增長�����,硬件方面也需要再次考慮����。
圖7
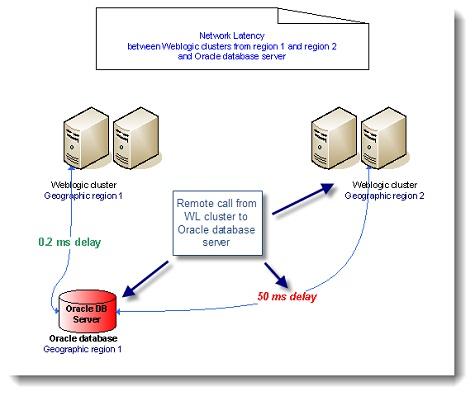
10.網絡延遲
最后一個影響性能問題的是網絡,網絡問題時不時的都會發(fā)生�,如路由器、交換機和DNS服務器失敗����。更常見的是在一個高度分散的IT環(huán)境中定期或間歇性延遲。下面圖片中的例子是一個位于同一區(qū)域的Weblogic集群通信與Oracle數據庫服務器之間的延遲���。
圖8
間歇或定期的延遲會觸發(fā)一些重要的性能問題,以不同的方式影響Java EE應用程序���。
因為大量的fetch迭代(網絡傳入和傳出)�����,涉及大數據集的數據查詢問題的應用會非常受網絡延遲的影響
應用程序在處理外部系統(tǒng)大數據負載(例如XML數據)時也會很受網絡延遲的影響���,會在發(fā)送和接收響應時產生巨大的響應間隔���。
Java EE容器復制過程(集群)也會受到影響���,并且會讓故障轉移功能(如多播或單播數據包損失)處于風險中。
JDBC行數據“預取”�、XML數據壓縮和數據緩存可以減少網絡延遲���。在設計一個新的網絡拓撲時���,應該仔細檢查這種網絡延遲問題�。
希望本文能夠幫助您理解一些常見的性能問題和壓力點�,每個IT環(huán)境都是獨一無二的�����,所以文中提到的問題不一定會是您遇到的�,您可以把您遇到的問題拿出來和大家一起分享一下!